VECTORES Y MATRICES (ARRAYS):
- Vector: Es un tipo de dato compuesto y estático. Todos son del mismo tipo.
Declaración
Nombre: ARRAY[1.....n] de tipo
Ej.: números:ARRAY[1.....5] de entero
viernes, 30 de marzo de 2012
miércoles, 28 de marzo de 2012
28 de marzo
ANIDAMIENTO DE INSTRUCCIONES
Ejemplo:
i:entero
j:entero
PARA i=0 HASTA 5
Inicio
PARA j=0 HASTA 3
Inicio
Escribir ("Hola")
Fin
Fin
-Calcular el mayor de tres numeros:
a:entero
b:entero
c:entero
Leer(a)
Leer(b)
Leer(c)
SI (a>b) AND (a>c)
Inicio
Escribir ("El mayor es a")
Fin
SINO
Inicio
SI (b>a) AND (b>c)
Inicio
Escribir
("El mayor es b")
Fin
SINO
Inicio
Escribir ("El mayor es c")
Fin
Fin
-Dada una fecha por teclado (dia,mes y año de tipo entero) que
salga por pantalla en el formato: 28 de Marzo de 2012.
d:entero
m:entero
a:entero
Escribir ("Dime el dia (1-31)")
Leer (d)
Escribir ("Dime el numero de mes (1-12)")
Leer (m)
Escribir("Dime el año")
Leer (a)
CASO (mes)
Inicio
Valor 1:
Inicio
Escribir( "La fecha es", d, "enero", a)
Fin
.
.
.
Valor 12:
Inicio
Escribir( "La fecha es", d, "diciembre", a)
Fin
Fin
ESTRUCTURA GENERAL DE UN PROGRAMA
PROGRAMA nombre
INICIO
VAR
a:entero
b:real DECLARACIONES
c:cadena
.
. IMPLEMENTACION
(Instrucciones)
.
FIN
-Ejercicio divisores con la estructura
PROGRAMA divisores
INICIO
VAR
a:entero
i:entero
ESCRIBE (“Introduce un numero: “)
LEER (a)
PARA i=1 HASTA a
INICIO
SI (a MOD i
=0)
INICIO
Escribe(i, ”es
divisor de”, a)
FIN
FIN
FIN
martes, 27 de marzo de 2012
INSTRUCCIONES
Primero, un ejercicio para recordar clases anteriores:
- Realizar una función que compruebe si el valor de una variable está comprendido entre el -5 y el 100.
Resultado: (a>-5) AND (a<100)
INSTRUCCIONES
Las instrucciones rompen la secuencialidad de un programa.
Son la máxima de la programación estructurada.
Existen varios tipos de instrucciones:
Síntaxis:
SI (<expresión>)
INICIO
.
.
.
FIN
Si la exprexión devuelve Verdadero, entonces se ejecuta el cuerpo de la instrucción. Si la expresión devuelve Falso, entonces no se ejecuta y salta directamente al FIN.
Ejemplo:
a <-- 101
SI (a>0)
INICIO
escribe ("Es positivo")
FIN
En este caso, como 101 es mayor que 0, la expresión se cumple y se ejecutaría el cuerpo. Con lo cual, imprimiría en pantalla "Es positivo".
ALTERNATIVA DOBLE O COMPUESTA:
Síntaxis:
SI (<expresión>)
INICIO
.
.
.
FIN
SINO
INICIO
.
.
.
FIN
Primero evalúa la primera expresión. Si esta es Verdadera, ejecuta el cuerpo de esa primera instrucción. Si devuelve falso, ejecutaría el cuerpo de la segunda instrucción.
Ejemplo:
a <-- 999
SI (a > 0)
INICIO
escribir ("Es positivo")
FIN
SINO
INICIO
escribir ("Es negativo")
FIN
En este caso, 999 es mayor que 0, por lo cual, se ejecutaría la primera instrucción e imprimiría en pantalla "Es positivo". Si a <-- -5, la primera instrucción devolvería Falso, y ejecutaría la siguiente, imprimiendo en pantalla "Es negativo".
ALTERNATIVA MÚLTIPLE:
Síntaxis:
CASO (variable)
INICIO
VALOR: 1
INICIO
.
.
.
FIN
VALOR: 2
INICIO
.
.
.
FIN
SINO
INICIO
.
.
.
FIN
FIN
En este caso tenemos varios cuerpos (3).
Primero evalúa el primer Valor: 1, si devuelve Verdadero, ejecuta la instrucción.
Si devuelve Falso, salta a evaluar el Valor: 2. Si este devuelve Verdadero, ejecuta su instrucción.
Si devuelve Falso, salta al último cuerpo y ejecuta su instrucción.
Ejemplo:
opcion <-- "a"
CASO (opcion)
INICIO
VALOR: "a"
INICIO
escribir ("Has elegido la primera opción")
FIN
VALOR: "b"
INICIO
escribir ("Has elegido la segunda opción")
FIN
SINO
INICIO
escribir ("Opción incorrecta")
FIN
FIN
Nota: El último SINO, no es obligatorio. Si ninguna condición se cumple, simplemente no se ejecuta nada.
EJERCICIOS PRÁCTICOS:
1. Leer dos datos de teclado (2 números) y que el programa nos diga cual es el mayor.
Resultado:
leer (a)
leer (b)
SI (a>b)
INICIO
escribir ("El número mayor es ", a)
FIN
SINO
INICIO
escribir ("El número mayor es ", b)
FIN
2. Leer un número de teclado. Comprobar si el número introducido es par.
Resultado:
leer (a)
SI (a mod2 = 0)
INICIO
escribir ("el número es par")
FIN
SINO
INICIO
escribir ("el número es impar")
FIN
NOTA: CONCATENACIÓN DE LITERALES Y VARIABLES.
Si en una frase queremos escribir cadenas de texto (literales) y variables juntas, debemos introducir las cadenas de texto entre comillas "", y concatenar la variable con una coma (,).
Ejemplo:
nombre <-- pepe
"Hola ", nombre
REPETITIVA MIENTRAS
Síntaxis:
MIENTRAS (condicion)
INICIO
.
.
.
FIN
Quiere decir, que mientras la condición devuelva Verdadero, se va a ejecutar la instrucción una y otra vez, hasta que la condición devuelva Falso.
Si la primera evaluación devuelve Falso, entonces no se llega a ejecutar la instrucción ninguna vez.
Ejemplo:
a <-- 10
MIENTRAS (a>=0)
INICIO
escribir (a)
a <-- a-1
FIN.
En este ejemplo la variable "a" vale 10.
La condición dice que mientras "a" sea igual o mayor que 0, se ejecute "Escribir (a)",
Después al valor de "a" en ese momento se le resta 1, y se vuelve a evaluar.
Ahora "a" valdrá 9. Como la condición se sigue cumpliendo, se escribirá en pantalla el número 9 y se le volverá a restar 1.
Así hasta que "a" valga -1. En ese caso la condición devuelve Falso, y termina el bucle.
Este ejemplo imprime en pantalla: 109876543210
REPETITIVA HASTA:
Síntaxis:
REPETIR
INICIO
.
.
.
FIN
HASTA (condicion)
En este tipo de instrucción repetitiva, primero se ejecuta el cuerpo y luego se evalúa la condición. Si ésta es Verdadera, se vuelve a ejecutar el cuerpo. así hasta que la condición sea Falsa.
La mayor diferencia con la instrucción REPETITIVA MIENTRAS, es que en este caso, el cuerpo se ejecuta al menos una vez.
Ejemplo:
a <-- 10
REPETIR
INICIO
escribir (a)
a <-- a-1
FIN
HASTA (a => 0)
REPETITIVA PARA
Síntaxis:
PARA variable = valor1 HASTA valor2
INICIO
.
.
.
FIN
En este tipo, se repite el cuerpo del bucle tantas veces como el rango de valores hayamos especificado en la variable.
Ejemplo:
i <-- 10
PARA i = 10 HASTA 0
INICIO
escribir (i)
FIN
Se repite hasta que el valor 1 alcanza el valor2, incrementando o decrementando según sea necesario.
Por ejemplo, si valor1 es 10 y valor2 es 20, irá incrementado valor hasta que llegue a 20 (inclusives).
Si valor1 es 20 y valor2 es 10, irá decrementando valor hasta que llegue a 10 (inclusives).
EJERCICIO FINAL
Dado un número por teclado, escribir la tabla de multiplicar de ese número:
Resultado:
leer (a)
PARA b = 0 HASTA 10
INICIO
escribir (a, "x", b, "= ", a*b)
FIN
by Dani (Foxmulder).
- Realizar una función que compruebe si el valor de una variable está comprendido entre el -5 y el 100.
Resultado: (a>-5) AND (a<100)
INSTRUCCIONES
Las instrucciones rompen la secuencialidad de un programa.
Son la máxima de la programación estructurada.
Existen varios tipos de instrucciones:
- INSTRUCCIONES ALTERNATIVAS:
- Simples.
- Dobles (o compuestas).
- Múltiples. - REPETITIVAS:
- Mientras.
- Hasta.
- Para.
Síntaxis:
SI (<expresión>)
INICIO
.
.
.
FIN
Si la exprexión devuelve Verdadero, entonces se ejecuta el cuerpo de la instrucción. Si la expresión devuelve Falso, entonces no se ejecuta y salta directamente al FIN.
Ejemplo:
a <-- 101
SI (a>0)
INICIO
escribe ("Es positivo")
FIN
En este caso, como 101 es mayor que 0, la expresión se cumple y se ejecutaría el cuerpo. Con lo cual, imprimiría en pantalla "Es positivo".
ALTERNATIVA DOBLE O COMPUESTA:
Síntaxis:
SI (<expresión>)
INICIO
.
.
.
FIN
SINO
INICIO
.
.
.
FIN
Primero evalúa la primera expresión. Si esta es Verdadera, ejecuta el cuerpo de esa primera instrucción. Si devuelve falso, ejecutaría el cuerpo de la segunda instrucción.
Ejemplo:
a <-- 999
SI (a > 0)
INICIO
escribir ("Es positivo")
FIN
SINO
INICIO
escribir ("Es negativo")
FIN
En este caso, 999 es mayor que 0, por lo cual, se ejecutaría la primera instrucción e imprimiría en pantalla "Es positivo". Si a <-- -5, la primera instrucción devolvería Falso, y ejecutaría la siguiente, imprimiendo en pantalla "Es negativo".
ALTERNATIVA MÚLTIPLE:
Síntaxis:
CASO (variable)
INICIO
VALOR: 1
INICIO
.
.
.
FIN
VALOR: 2
INICIO
.
.
.
FIN
SINO
INICIO
.
.
.
FIN
FIN
En este caso tenemos varios cuerpos (3).
Primero evalúa el primer Valor: 1, si devuelve Verdadero, ejecuta la instrucción.
Si devuelve Falso, salta a evaluar el Valor: 2. Si este devuelve Verdadero, ejecuta su instrucción.
Si devuelve Falso, salta al último cuerpo y ejecuta su instrucción.
Ejemplo:
opcion <-- "a"
CASO (opcion)
INICIO
VALOR: "a"
INICIO
escribir ("Has elegido la primera opción")
FIN
VALOR: "b"
INICIO
escribir ("Has elegido la segunda opción")
FIN
SINO
INICIO
escribir ("Opción incorrecta")
FIN
FIN
Nota: El último SINO, no es obligatorio. Si ninguna condición se cumple, simplemente no se ejecuta nada.
EJERCICIOS PRÁCTICOS:
1. Leer dos datos de teclado (2 números) y que el programa nos diga cual es el mayor.
Resultado:
leer (a)
leer (b)
SI (a>b)
INICIO
escribir ("El número mayor es ", a)
FIN
SINO
INICIO
escribir ("El número mayor es ", b)
FIN
2. Leer un número de teclado. Comprobar si el número introducido es par.
Resultado:
leer (a)
SI (a mod2 = 0)
INICIO
escribir ("el número es par")
FIN
SINO
INICIO
escribir ("el número es impar")
FIN
NOTA: CONCATENACIÓN DE LITERALES Y VARIABLES.
Si en una frase queremos escribir cadenas de texto (literales) y variables juntas, debemos introducir las cadenas de texto entre comillas "", y concatenar la variable con una coma (,).
Ejemplo:
nombre <-- pepe
"Hola ", nombre
REPETITIVA MIENTRAS
Síntaxis:
MIENTRAS (condicion)
INICIO
.
.
.
FIN
Quiere decir, que mientras la condición devuelva Verdadero, se va a ejecutar la instrucción una y otra vez, hasta que la condición devuelva Falso.
Si la primera evaluación devuelve Falso, entonces no se llega a ejecutar la instrucción ninguna vez.
Ejemplo:
a <-- 10
MIENTRAS (a>=0)
INICIO
escribir (a)
a <-- a-1
FIN.
En este ejemplo la variable "a" vale 10.
La condición dice que mientras "a" sea igual o mayor que 0, se ejecute "Escribir (a)",
Después al valor de "a" en ese momento se le resta 1, y se vuelve a evaluar.
Ahora "a" valdrá 9. Como la condición se sigue cumpliendo, se escribirá en pantalla el número 9 y se le volverá a restar 1.
Así hasta que "a" valga -1. En ese caso la condición devuelve Falso, y termina el bucle.
Este ejemplo imprime en pantalla: 109876543210
REPETITIVA HASTA:
Síntaxis:
REPETIR
INICIO
.
.
.
FIN
HASTA (condicion)
En este tipo de instrucción repetitiva, primero se ejecuta el cuerpo y luego se evalúa la condición. Si ésta es Verdadera, se vuelve a ejecutar el cuerpo. así hasta que la condición sea Falsa.
La mayor diferencia con la instrucción REPETITIVA MIENTRAS, es que en este caso, el cuerpo se ejecuta al menos una vez.
Ejemplo:
a <-- 10
REPETIR
INICIO
escribir (a)
a <-- a-1
FIN
HASTA (a => 0)
REPETITIVA PARA
Síntaxis:
PARA variable = valor1 HASTA valor2
INICIO
.
.
.
FIN
En este tipo, se repite el cuerpo del bucle tantas veces como el rango de valores hayamos especificado en la variable.
Ejemplo:
i <-- 10
PARA i = 10 HASTA 0
INICIO
escribir (i)
FIN
Se repite hasta que el valor 1 alcanza el valor2, incrementando o decrementando según sea necesario.
Por ejemplo, si valor1 es 10 y valor2 es 20, irá incrementado valor hasta que llegue a 20 (inclusives).
Si valor1 es 20 y valor2 es 10, irá decrementando valor hasta que llegue a 10 (inclusives).
EJERCICIO FINAL
Dado un número por teclado, escribir la tabla de multiplicar de ese número:
Resultado:
leer (a)
PARA b = 0 HASTA 10
INICIO
escribir (a, "x", b, "= ", a*b)
FIN
by Dani (Foxmulder).
lunes, 26 de marzo de 2012
Dia 26
Bases de datos
Seguimos practicando los modelos entidad-relación con ejercicios escritos e intentando aplicar los modelos de normalización de bases de datos que hemos visto en los días anteriores...(pincha aquí para ver) el dia se plantea largo....
Juanma se encarga de resolver el ejercicio propuesto por Teo:
.JPG)
No lo hace ni bien ni mal... regular lo dejaremos así...
.JPG)
No lo hace ni bien ni mal... regular lo dejaremos así...
Fin del dia! un dia prospero pero poco apasionante, esto de tener a Juama todo el día dando el coñazo aburre...

NORMALIZACION DE LA BBD RELACIONALES
viernes 23 de marzo de 2012
Las bases de datos relacionales se normalizan para:
- Evitar la redundancia de los datos.
- Evitar problemas de actualización de los datos en las tablas.
- Proteger la integridad de los datos.
- Cada tabla debe tener su nombre único.
- No puede haber dos filas iguales. No se permiten los duplicados.
- Todos los datos en una columna deben ser del mismo tipo.
Terminología relacional equivalente

- Relación = tabla o archivo
- Registro = registro, fila , renglón o tupla
- Atributo = columna o campo
- Clave = llave o código de identificación
- Clave Candidata = superclave mínima
- Clave Primaria = clave candidata elegida
- Clave Ajena (o foránea) = clave externa o clave foránea
- Clave Alternativa = clave secundaria
- Dependencia Multivaluada = dependencia multivalor
- RDBMS = Del inglés Relational Data Base Manager System que significa, Sistema Gestor de Bases de Datos Relacionales.
- 1FN = Significa, Primera Forma Normal o 1NF del inglés First Normal Form.
Todo atributo en una tabla tiene un dominio, el cual representa el conjunto de valores que el mismo puede tomar. Una instancia de una tabla puede verse entonces como un subconjunto del producto cartesiano entre los dominios de los atributos. Sin embargo, suele haber algunas diferencias con la analogía matemática, ya que algunos RDBMS permiten filas duplicadas, entre otras cosas. Finalmente, una tupla puede razonarse matemáticamente como un elemento del producto cartesiano entre los dominio.
Dependencia
Dependencia funcional

Las dependencias funcionales del sistema se escriben utilizando una flecha, de la siguiente manera:
FechaDeNacimiento
 EdadDe
la normalización (lógica) a la implementación (física o real) puede
ser sugerible tener éstas dependencias funcionales para lograr la
eficiencia en las tablas.
EdadDe
la normalización (lógica) a la implementación (física o real) puede
ser sugerible tener éstas dependencias funcionales para lograr la
eficiencia en las tablas.Propiedades de la Dependencia funcional
Existen 3 axiomas de Armstrong:Dependencia funcional Reflexiva
Si "x" está incluido en "x" entonces x
x A partir de cualquier atributo o conjunto de atributos siempre puede
deducirse él mismo. Si la dirección o el nombre de una persona están
incluidos en el DNI, entonces con el DNI podemos determinar la dirección
o su nombre.Dependencia funcional Aumentativa
 entonces
entonces 
DNI
nombreDNI,dirección
nombre,direcciónSi con el DNI se determina el nombre de una persona, entonces con el DNI más la dirección también se determina el nombre y su dirección.
Dependencia funcional transitiva

X
Y Z entonces X ZFechaDeNacimiento
EdadEdad
ConducirFechaDeNacimiento
Edad ConducirEntonces tenemos que FechaDeNacimiento determina a Edad y la Edad determina a Conducir, indirectamente podemos saber a través de FechaDeNacimiento a Conducir (En muchos países, una persona necesita ser mayor de cierta edad para poder conducir un automóvil, por eso se utiliza este ejemplo).
Propiedades deducidas
Unión
y  entonces
entonces 
Pseudo-transitiva
y  entonces
entonces 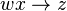
Descomposición
y 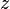 está incluido en
está incluido en  entonces
entonces Claves
Una clave primaria es aquella columna (o conjunto de columnas) que identifica únicamente a una fila. La clave primaria es un identificador que va a ser siempre único para cada fila. Se acostumbra a poner la clave primaria como la primera columna de la tabla pero es más una conveniencia que una obligación. Muchas veces la clave primaria es numérica auto-incrementada, es decir, generada mediante una secuencia numérica incrementada automáticamente cada vez que se inserta una fila.En una tabla puede que tengamos más de una columna que puede ser clave primaria por sí misma. En ese caso se puede escoger una para ser la clave primaria y las demás claves serán claves candidatas.
Una clave ajena (foreign key o clave foránea) es aquella columna que existiendo como dependiente en una tabla, es a su vez clave primaria en otra tabla.
Una clave alternativa es aquella clave candidata que no ha sido seleccionada como clave primaria, pero que también puede identificar de forma única a una fila dentro de una tabla. Ejemplo: Si en una tabla clientes definimos el número de documento (id_cliente) como clave primaria, el número de seguro social de ese cliente podría ser una clave alternativa. En este caso no se usó como clave primaria porque es posible que no se conozca ese dato en todos los clientes.
Una clave compuesta es una clave que está compuesta por más de una columna.
La visualización de todas las posibles claves candidatas en una tabla ayudan a su optimización. Por ejemplo, en una tabla PERSONA podemos identificar como claves su DNI, o el conjunto de su nombre, apellidos, fecha de nacimiento y dirección. Podemos usar cualquiera de las dos opciones o incluso todas a la vez como clave primaria, pero es mejor en la mayoría de sistemas la elección del menor número de columnas como clave primaria.
Formas Normales
Las formas normales son aplicadas a las tablas de una base de datos. Decir que una base de datos está en la forma normal N es decir que todas sus tablas están en la forma normal N.
Primera Forma Normal (1FN)
Una tabla está en Primera Forma Normal si:- Todos los atributos son atómicos. Un atributo es atómico si los elementos del dominio son indivisibles, mínimos.
- La tabla contiene una llave primaria única.
- La llave primaria no contiene atributos nulos.
- No debe existir variación en el número de columnas.
- Los Campos no llave deben identificarse por la llave (Dependencia Funcional)
- Debe Existir una independencia del orden tanto de las filas como de las columnas, es decir, si los datos cambian de orden no deben cambiar sus significados
Esta forma normal elimina los valores repetidos dentro de una BD
Segunda Forma Normal (2FN)
Dependencia Funcional. Una relación está en 2FN si está en 1FN y si los atributos que no forman parte de ninguna clave dependen de forma completa de la clave principal. Es decir que no existen dependencias parciales. (Todos los atributos que no son clave principal deben depender únicamente de la clave principal).En otras palabras podríamos decir que la segunda forma normal está basada en el concepto de dependencia completamente funcional. Una dependencia funcional
es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que  . Una dependencia funcional es una dependencia parcial si hay algunos atributos
. Una dependencia funcional es una dependencia parcial si hay algunos atributos  que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es
que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es  .
.Por ejemplo {DNI, ID_PROYECTO}
HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto
sabemos cuántas horas de trabajo por semana trabaja un empleado en
dicho proyecto) es completamente dependiente dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.Tercera Forma Normal (3FN)
La tabla se encuentra en 3FN si es 2FN y si no existe ninguna dependencia funcional transitiva entre los atributos que no son clave.Un ejemplo de este concepto sería que, una dependencia funcional X->Y en un esquema de relación R es una dependencia transitiva si hay un conjunto de atributos Z que no es un subconjunto de alguna clave de R, donde se mantiene X->Z y Z->Y.
Por ejemplo, la dependencia SSN->DMGRSSN es una dependencia transitiva en EMP_DEPT de la siguiente figura. Decimos que la dependencia de DMGRSSN el atributo clave SSN es transitiva vía DNUMBER porque las dependencias SSN→DNUMBER y DNUMBER→DMGRSSN son mantenidas, y DNUMBER no es un subconjunto de la clave de EMP_DEPT. Intuitivamente, podemos ver que la dependencia de DMGRSSN sobre DNUMBER es indeseable en EMP_DEPT dado que DNUMBER no es una clave de EMP_DEPT.
Formalmente, un esquema de relacion
 está en 3 Forma Normal Elmasri-Navathe,2 si para toda dependencia funcional
está en 3 Forma Normal Elmasri-Navathe,2 si para toda dependencia funcional 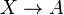 , se cumple al menos una de las siguientes condiciones:
, se cumple al menos una de las siguientes condiciones: es superllave o clave.
es superllave o clave. es atributo primo de ; esto es, si es miembro de alguna clave en .
es atributo primo de ; esto es, si es miembro de alguna clave en .
Forma normal de Boyce-Codd (FNBC)
La tabla se encuentra en FNBC si cada determinante, atributo que determina completamente a otro, es clave candidata. Deberá registrarse de forma anillada ante la presencia de un intervalo seguido de una formalizacion perpetua, es decir las variantes creadas, en una tabla no se llegaran a mostrar, si las ya planificadas, dejan de existir.Formalmente, un esquema de relación
está en FNBC, si y sólo si, para toda dependencia funcional válida en , se cumple que- es superllave o clave.
que cumple FNBC, está además en 3FN; sin embargo, no todo esquema que cumple con 3FN, está en FNBC.Cuarta Forma Normal (4FN)
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X->->Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si:- La tabla está en 4FN
- No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que está en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
Reglas de Codd
Codd se percató de que existían bases de datos en el mercado las cuales decían ser relacionales, pero lo único que hacían era guardar la información en las tablas, sin estar estas tablas literalmente normalizadas; entonces éste publicó 12 reglas que un verdadero sistema relacional debería tener, en la práctica algunas de ellas son difíciles de realizar. Un sistema podrá considerarse "más relacional" cuanto más siga estas reglas.Regla No. 1 - La Regla de la información
Toda la información en un RDBMS está explícitamente representada de una sola manera por valores en una tabla.Cualquier cosa que no exista en una tabla no existe del todo. Toda la información, incluyendo nombres de tablas, nombres de vistas, nombres de columnas, y los datos de las columnas deben estar almacenados en tablas dentro de las bases de datos. Las tablas que contienen tal información constituyen el Diccionario de Datos. Esto significa que todo tiene que estar almacenado en las tablas.
Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas. Por tanto los metadatos (diccionario, catálogo) se representan exactamente igual que los datos de usuario. Y puede usarse el mismo lenguaje (ej. SQL) para acceder a los datos y a los metadatos (regla 4)
Regla No. 2 - La regla del acceso garantizado
Cada ítem de datos debe ser lógicamente accesible al ejecutar una búsqueda que combine el nombre de la tabla, su clave primaria, y el nombre de la columna.Esto significa que dado un nombre de tabla, dado el valor de la clave primaria, y dado el nombre de la columna requerida, deberá encontrarse uno y solamente un valor. Por esta razón la definición de claves primarias para todas las tablas es prácticamente obligatoria.
Regla No. 3 - Tratamiento sistemático de los valores nulos
La información inaplicable o faltante puede ser representada a través de valores nulosUn RDBMS (Sistema Gestor de Bases de Datos Relacionales) debe ser capaz de soportar el uso de valores nulos en el lugar de columnas cuyos valores sean desconocidos.
Regla No. 4 - La regla de la descripción de la base de datos
La descripción de la base de datos es almacenada de la misma manera que los datos ordinarios, esto es, en tablas y columnas, y debe ser accesible a los usuarios autorizados.La información de tablas, vistas, permisos de acceso de usuarios autorizados, etc, debe ser almacenada exactamente de la misma manera: En tablas. Estas tablas deben ser accesibles igual que todas las tablas, a través de sentencias de SQL (o similar).
Regla No. 5 - La regla del sub-lenguaje Integral
Debe haber al menos un lenguaje que sea integral para soportar la definición de datos, manipulación de datos, definición de vistas, restricciones de integridad, y control de autorizaciones y transacciones.Esto significa que debe haber por lo menos un lenguaje con una sintaxis bien definida que pueda ser usado para administrar completamente la base de datos.
Regla No. 6 - La regla de la actualización de vistas
Todas las vistas que son teóricamente actualizables, deben ser actualizables por el sistema mismo.La mayoría de las RDBMS permiten actualizar vistas simples, pero deshabilitan los intentos de actualizar vistas complejas.
Regla No. 7 - La regla de insertar y actualizar
La capacidad de manejar una base de datos con operandos simples aplica no sólo para la recuperación o consulta de datos, sino también para la inserción, actualización y borrado de datos'.Esto significa que las cláusulas para leer, escribir, eliminar y agregar registros (SELECT, UPDATE, DELETE e INSERT en SQL) deben estar disponibles y operables, independientemente del tipo de relaciones y restricciones que haya entre las tablas o no.
Regla No. 8 - La regla de independencia física
El acceso de usuarios a la base de datos a través de terminales o programas de aplicación, debe permanecer consistente lógicamente cuando quiera que haya cambios en los datos almacenados, o sean cambiados los métodos de acceso a los datos.El comportamiento de los programas de aplicación y de la actividad de usuarios vía terminales debería ser predecible basados en la definición lógica de la base de datos, y éste comportamiento debería permanecer inalterado, independientemente de los cambios en la definición física de ésta.
Regla No. 9 - La regla de independencia lógica
Los programas de aplicación y las actividades de acceso por terminal deben permanecer lógicamente inalteradas cuando quiera que se hagan cambios (según los permisos asignados) en las tablas de la base de datos.La independencia lógica de los datos especifica que los programas de aplicación y las actividades de terminal deben ser independientes de la estructura lógica, por lo tanto los cambios en la estructura lógica no deben alterar o modificar estos programas de aplicación.
Regla No. 10 - La regla de la independencia de la integridad
Todas las restricciones de integridad deben ser definibles en los datos, y almacenables en el catalogo, no en el programa de aplicación.Las reglas de integridad
- Ningún componente de una clave primaria puede tener valores en blanco o nulos (ésta es la norma básica de integridad).
- Para cada valor de clave foránea deberá existir un valor de clave primaria concordante. La combinación de estas reglas aseguran que haya integridad referencial. Regla No. 11 - La regla de la distribución
El soporte para bases de datos distribuidas significa que una colección arbitraria de relaciones, bases de datos corriendo en una mezcla de distintas máquinas y distintos sistemas operativos y que esté conectada por una variedad de redes, pueda funcionar como si estuviera disponible como en una única base de datos en una sola máquina.
Regla No. 12 - Regla de la no-subversión
Si el sistema tiene lenguajes de bajo nivel, estos lenguajes de ninguna manera pueden ser usados para violar la integridad de las reglas y restricciones expresadas en un lenguaje de alto nivel (como SQL).Algunos productos solamente construyen una interfaz relacional para sus bases de datos No relacionales, lo que hace posible la subversión (violación) de las restricciones de integridad. Esto no debe ser permitido.
En esta pagina se ve un ejemplo:
Suscribirse a:
Entradas (Atom)